
python爬取cs193p课件
最近在上stanford的cs193p的课程,闲着没事,先将它的课件用python从网上爬了下来…
目标网站
CS 193P iPhone Application Development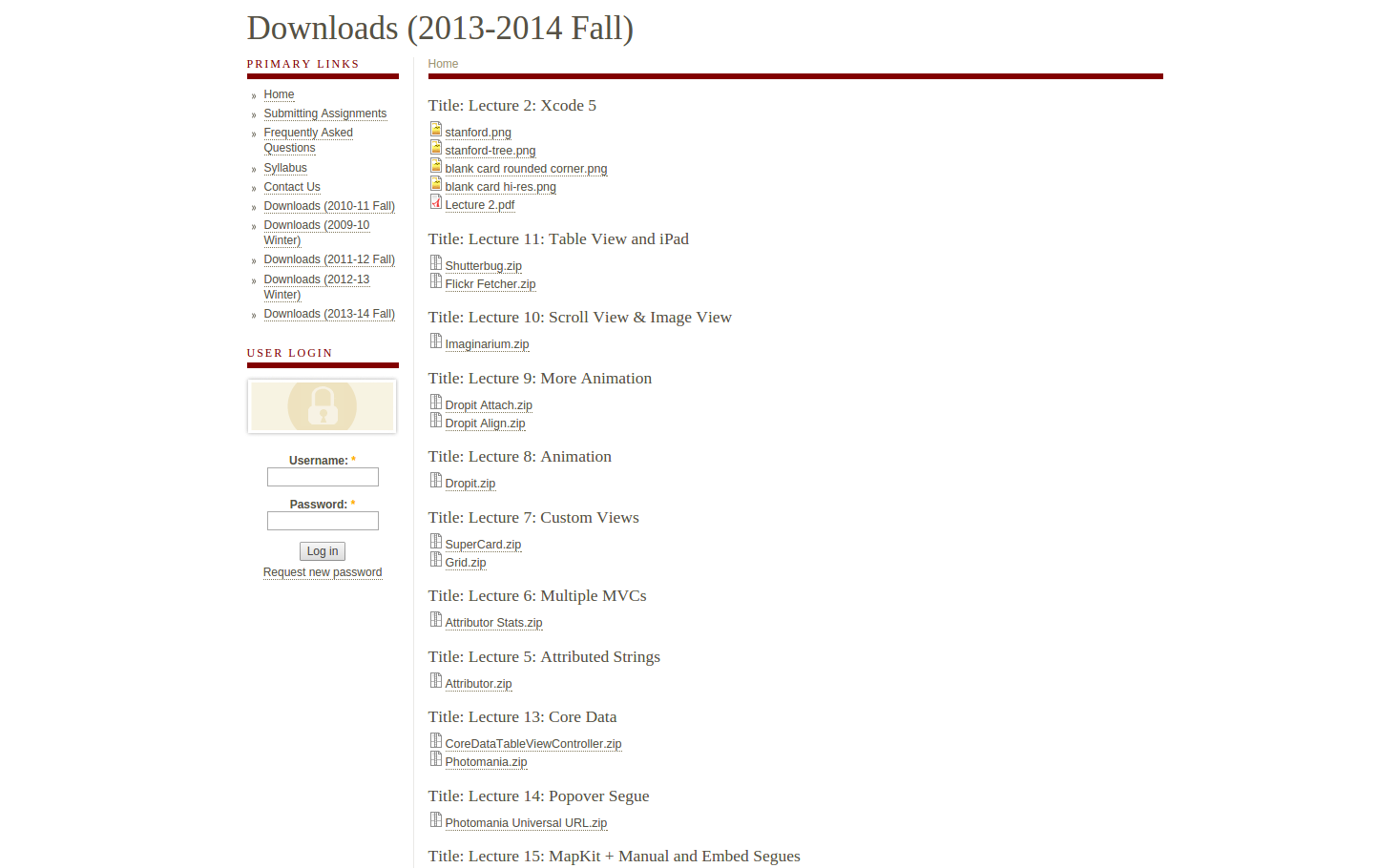
先看源码
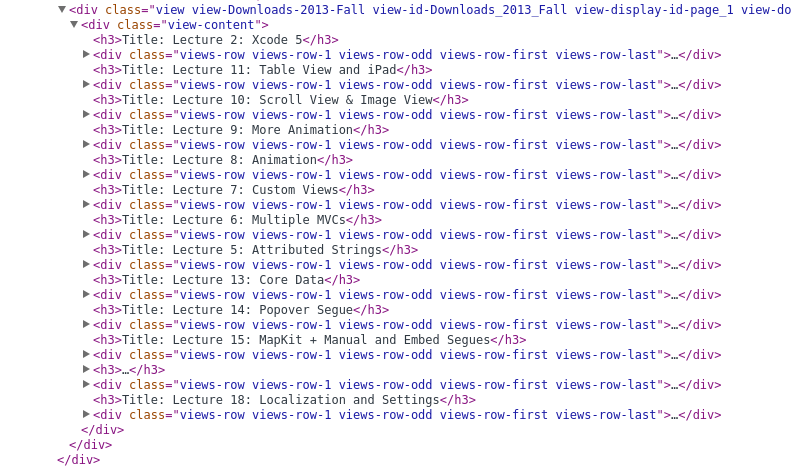 在class=view-content的div里面是所需的课件的下载链接,他们以<h3$gt;和<div>的顺序排列。
看看每个<div>的具体内容
在class=view-content的div里面是所需的课件的下载链接,他们以<h3$gt;和<div>的顺序排列。
看看每个<div>的具体内容
 每一个<div>下面的<a>标签里面的href链接所对应的内容都应该下载下来
每一个<div>下面的<a>标签里面的href链接所对应的内容都应该下载下来
show me the code
mkdir.sh
#!/bin/sh
for var in 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
do
mkdir $var
done创建多个目录,用来存放每节课的lecture
download-lecture.py
import os
import requests
import bs4
import reoriginal_url = ‘http://www.stanford.edu/class/cs193p/cgi-bin/drupal/downloads-2013-fall‘
response = requests.get(original_url)
html = response.text
soup = bs4.BeautifulSoup(html)view_content = soup.findAll(“div”, {“class” : “view-content”})
lectures = view_content[0].findAll(“h3”);
for lecture in lectures:
lecture_title = lecture.text
lecture_content = lecture.findNextSibling(“div”)
sample = lecture_content.find(“div”, {“class” : “views-field-field-sample-code-fid”})
slide = lecture_content.find(“div”, {“class” : “views-field-field-lecture-slides-fid”})#regular expression
pattern = re.compile(r’Title: Lecture’);
match = pattern.match(lecture_title);
if match:
title_array = lecture_title.split(‘: Lecture’);
lecture_num = ((title_array[1].split(‘ ‘))[1].split(‘:’))[0]
else:
continuesample_urls = sample.findAll(‘a’)
slide_urls = slide.findAll(‘a’)current_dir = ‘cd ‘ + lecture_num
os.system(current_dir)
for sample_url in sample_urls:
href = sample_url[‘href’]
os.system(current_dir + ‘ && wget ‘ + href)
for slide_url in slide_urls:
href = slide_url[‘href’]
os.system(current_dir + ‘ && wget ‘ + href)使用了BeautifulSoup来分析HTML代码